Our lab recently got three papers published in a single issue of Angewandte Chemie about our work incorporating graph theory into chemistry (here, here, and here!). Among these was my first first-author paper, which is a biggish deal in the science world. So, that’s exciting.
Although the three papers address different issues, their underlying approaches are very similar. By viewing chemistry as a connected network, we can imagine algorithms that “traverse” reactions. In my head, this is nothing more than the merging of two popular fields. In fact, I was originally surprised that there was so little on the topic - especially with the growth of cheminformatics over recent years. However, I’ve come to find that synthetic chemistry is an astoundingly conservative field, and people are slow to adopt technologies out of their expertise. Either that, or I’m terrible at doing lit searches. Probably both.
First, let’s discuss chemistry as a connected network. You often see reactions written as A + B -> C + D, which is useful in showcasing a single reaction. But what if you want to show multiple reactions? The standard notation falls apart rather quickly, and most chemists will find that they’ll start drawing arrows differently. In fact, I’d argue that most chemists already view complex sets of a reactions as a network - they just never had a term for it.
As an example, let’s take a set of related reactions and write them out in standard notation.
B + E -> F + G
D + H -> I + J
F + J -> K
I + J -> L + M
K + M -> N
N + E -> G
The letters are all placeholders for chemical formulas, which I’m leaving out for simplicity. It’s short and concise, but this representation doesn’t show how the reactions interconnect. In network representation, this would look like:
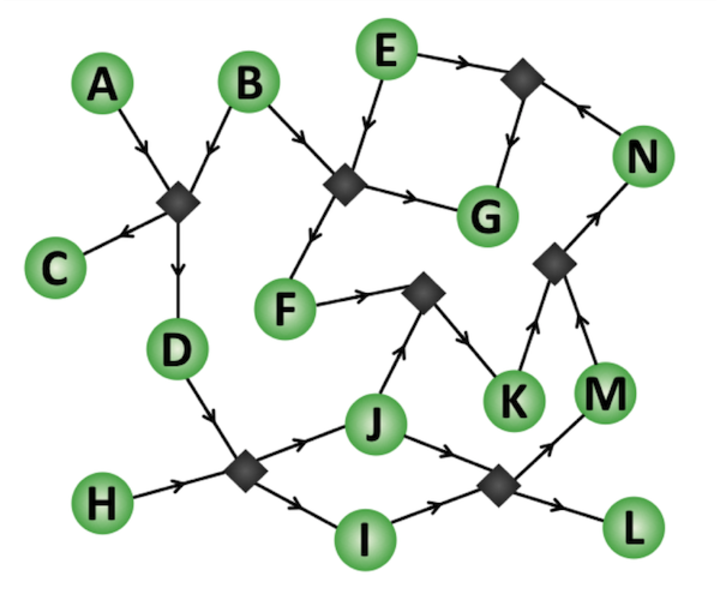
Here, the green circle nodes represent chemicals and the black diamonds represent reactions. I added in the black diamonds to simplify arrows, so it’s easier to see how the chemicals react with each other.
I think that many chemists already sketch synthetic routes like this. Starting from simple precursors like ethanol, work your way to a target chemical. You’ll have arrows pointing everywhere, with your thought process based around a carbon backbone. Once you think of chemistry in this manner, everything else in these papers is very logical.
In two of the papers, we discuss methods for algorithmically generating synthetic routes to targets. By finding a way to score chemicals and reactions, we can optimize routes. In fact, this “scoring” is the only real difference between the papers.
There’s still a lot of work to be done in this area, but I think that the current algorithms already provide evidence of the efficacy of the network approach. If we can automate and simplify the more repetitive portions of synthetic route discovery, we can give chemists more time to, well, do chemistry.
